双塔召回模型
目前推荐系统中最重要的模型类型之一是双塔神经网络。它们的结构如下:神经网络的一部分(塔)处理有关查询(用户、上下文)的所有信息,而另一部分处理有关对象的信息。这些塔的输出是embedding相关特征,然后将它们相乘(内积或余弦相似度)得到user跟item的匹配分。
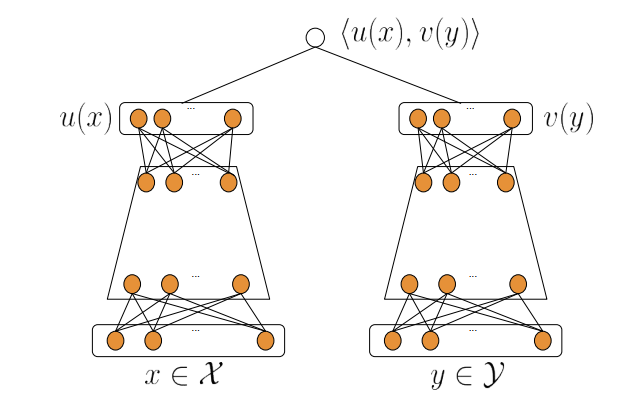
它与矩阵分解非常相似,实际上矩阵分解可以看做双塔模型的一个特例,只接受user_id和item_id作为输入,没有中间的MLP层。
相比一般的MLP模型,最后才交叉user和item的特征使双塔网络在应用中极其高效。要为单个用户构建推荐,我们需要计算一次user塔向量,然后将得到的user向量与文档向量计算内积,而文档向量通常是预先计算好的,这个过程的计算量就比一般的MLP网络快很多。此外,这些预先计算的item向量可以组织成ANN索引(例如HNSW),从而无需遍历整个数据库即可快速找到好的候选。
损失函数和负采样
原则上,我们可以用任何损失函数进行训练。不过通常我们会倾向于在batch内负样本上使用 inbatch-softmax 损失进行训练,假设我们以点击为目标,训练样本只保留了点击的<user, item>样本,这样每个batch内的<user, item>对都是正样本,而将其他的item都作为user的负样本。那么训练任务可以看做一个多分类任务,batch内的每一个item是一个类别,当前user会点击每个item的概率为:
$$P(y_i | x_i) = \frac{e^{s(x_i, y_i)}}{\sum_{j\in B} e^{s(x_i, y_j)}} $$
对应的损失函数为
$$loss_{i} = – \log P(y_i|x_i)$$
inbatch-softmax损失的TensorFlow实现如下:
# 假设 user_embedding是用户塔输出的向量, group_embedding 为item塔输出的向量
def inbatch_softmax_loss(user_embedding, group_embedding):
"""
user_embedding: [B, n]
group_embedding: [B, n]
"""
C = 10
batch_logits = C * tf.matmul(user_embedding, group_embedding,transpose_b=True) # [B, B]
batch_pred = tf.nn.softmax(batch_logits)
batch_label = tf.eye(tf.shape(batch_logits)[0]) # [B, B]
batch_loss = tf.nn.softmax_cross_entropy_with_logits_v2(labels=soft_label, logits=batch_logits) # [B, ]
return tf.reduce_sum(batch_loss)这里的C是一个超参数,通常user塔和item塔的输出向量我们会做L2归一化,那么内积的值就在[-1, 1] 之间了,所以我们需要做一下缩放。
另外,由于我们将batch内的item作为负样本,这天然会导致热门的item成为负样本的概率越高。我们期望是item集合里的每个item成为负样本的概率要基本相等,那么这将导致模型过度打压热门item。Google 在一篇论文中建议在训练期间使用 logQ 校正来解决这个问题。
logQ矫正
对每个item j,假设被采样的概率为 \(p_j\),那么log Q矫正就是在本来的内积上加上 \(-\log p_j\)
$$s^c(x_i, y_j) = s(x_i, y_j) – \log p_j$$
$p_j$的概率通过距离上一次看到y的间隔来估计,item越热门,训练过程中就越经常看到item,那么距离上次看到y的间隔B(y)跟概率p成反比。于是有如下算法

在实践当中,对每个y都可以用PS的1维向量来存储对应的step,那么下一次再看到y时就可以计算出对应的间隔和概率了。
step = get_global_step() # 获取当前的batch计数tensor
item_step = get_item_step_vector() # 获取用于存储item上次见过的step的向量
item_step.set_gradient(grad=step - item_step, lr=1.0)
delta = tf.clip_by_value(step - item_step, 1, 1000)
logq = tf.stop_gradient(tf.log(delta))
batch_logits += logq # batch_logits 是前面计算的logits
...get_global_step和get_item_step_vector 通常取决于PS的实现,不同的平台api不太一样。
item_step通过学习率lr=1.0的梯度更新,更新为新的step。
$$z = z_{old} – lr * (z – z_{old}) = z $$
参考论文
- Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations,下载